字符串基础
1.字符串匹配
1.暴力算法
for (i = 0; i < n - m + 1; i++) {
for (j = 0; j < m; j++) {
if (a[i + j] != b[j]) break;
}
if (j == m) ans.push_back(i);
}
2.哈希
将string映射为int 每一个字符串代表一个数字 时间复杂度变为O(n+m)
转化方法可以采用 \(f(s) = \sum{s[i]*b^i}(modM)\)
ll hashs(char s[])//上述公式相当于把一个字符串看成一个b进制数
{
int len=strlen(s);
ll ans=0;
for (int i=0;i<len;i++)
ans=(ans*base+(ll)s[i])%mod;
return ans;
}
b与M应当是互质的(不然取余的时候直接约了)
在输入随机的情况下,这个求出的数在[0,M)上的值概率相等,所以单次比较重复的概率为
$\frac{1}{M}$ n次比较中出错的概率就为$1-(1-(1/M))^n$
当M»n时 这个值接近$\frac{n}{M}$
一般来说我们直接用ULL(unsigned long long类型)来储存Hash值,因为这个类型在$2^{64}$溢出时会自动对$2^{64}$取模
最长公共子串
给出几个由小写字母构成的单词,求它们最长的公共子串的长度。
任务
- 从文件中读入单词
- 计算最长公共子串的长度
- 输出结果到文件
输入
文件的第一行是整数 n,1<=n<=5,表示单词的数量。接下来n行每行一个单词,只由小写字母组成,单词的长度至少为1,最大为2000。
输出:
仅一行,一个整数,最长公共子串的长度。
样例输入:
3
abcb
bca
acbc
样例输出:
2
二分答案+哈希 或者 用后缀数组
哈希:(PS:map的[]是O(logn)的,所以这个过不了1e5的数据,如果n=2直接用vector就可以过1e5了)
#include <cstdio>
#include <string.h>
#include <map>
#include <algorithm>
using namespace std;
typedef unsigned long long ULL;
const int maxn = 1e5+10;
const ULL base = 27;
char s[7][maxn];
map<ULL, ULL> ans;
int n;
bool solve(int len){
ans.clear();
for(int i = 0;i < n; i++){
int t = strlen(s[i]);//该字符串长度
ULL tt = 0, temp = 1;//tt 当前进制数 temp 进制最高位
for(int j = 0;j < len; j++){
tt = tt*base+(ULL)(s[i][j]-'a');
if(j) temp=temp*base;
}
if(ans[tt]==i){
ans[tt]++;
if(ans[tt]==n){
return 1;
}
}
for(int j = len; j < t; j++){
tt=tt*base+(ULL)(s[i][j]-'a')-temp*(ULL)(s[i][j-len]-'a')*base;
if(ans[tt]==i){
ans[tt]++;
if(ans[tt]==n){
return 1;
}
}
}
}
return 0;
}
int main(){
//freopen("pow.in", "r", stdin);
//freopen("pow.out", "w", stdout);
int minl = maxn;
scanf("%d", &n);
for(int i= 0;i < n; i++){
scanf("%s", s[i]);
int t = strlen(s[i]);
minl = min(t, minl);
}
int l= 1, r = minl, ans = 0;
while(l<=r){
int mid = (l+r)/2;
if(solve(mid)){
ans = mid;
l = mid+1;
}
else r = mid-1;
}
printf("%d\n", ans);
return 0;
}
3.KMP
前缀数组
一个字符串的真前缀是其前缀但不等于该字符串自身。
对于一个字符串s,其前缀函数为$\pi$,其中$\pi$[i]指即是s[0~i]的前缀又是该子串后缀的最长真前缀
abcaabcab的前缀函数为[0,0,0,1,1,2,3,4, 2]
aabaaab的前缀函数为[0,1,0,1,2,2,3]
前缀数组最直观的求法 O($n^3$)
vector<int> prefix_function(string s) {
int n = s.length();
vector<int> pi;
for (int i = 0; i < n; i++)
for (int k = 0; k <= i; k++)
if (s[0 ~ k] == s[i - k + 1 ~ k]) pi[i] = k;
return pi;
}
KMP算法
观察前面的前缀函数例子,发现前缀函数后一位有三种情况
1.增加1(因为是最长真前缀,所以一定和之前一位只相差1)
2.保持不变
3.减少
观察减小的例子 如果当前字符s[i]与s[$\pi$[i-1]+1]不同,就不能加一
这时候我们去判断“前缀函数的前缀函数”即$\pi$[$\pi$[i-1]-1]
如果这时匹配了,那就加一
具体证明此处不赘述
vector<int> prefix_function(string s) {
int n = (int)s.length();
vector<int> pi(n);
for (int i = 1; i < n; i++) {
int j = pi[i - 1];
while (j > 0 && s[i] != s[j]) j = pi[j - 1];
if (s[i] == s[j]) j++;
pi[i] = j;
}
return pi;
}
$POJ 1961$
如果一个字符串 $S$ 是由一个字符串 $T$ 重复 $K$ 次形成的,则称 $T$ 为 $S$ 的循环元。使 $K$ 最大的字符串 $T$ 称为 $S$的最小循环元,此时的 $K$ 被称为最大的循环次数。
现在给定一个长度为 $N$ 的字符串 $S$ ,对 $S$ 的每一个前缀 $S[1$~$i]$ ,如果它的最大循环次数大于 $1$ ,则输出该前缀的最小循环长度和最大循环次数。
Sample Input
3
aaa
12
aabaabaabaab
0
Sample Output
Test case #1
2 2
3 3
Test case #2
2 2
6 2
9 3
12 4
$S[1$~ $i]$ 具有长度为了 $len$ < $i$ 的循环元的充要条件为 $len$ 能整除 $i$ 并且 $S[len + 1$~ $i] = S[1$~ $i - len]$
证明:
必要性 有长度为 $len$ 的循环元,那么显然 $len$ 能整除 $i$ 并且 $S[len + 1$~ $i]$ = $S[1$~ $i - len]$ 成立
充分性 $len$ 能整除 $i$ 并且 $S[len + 1$~ $i]$ = $S[1$~ $i - len]$ 成立。首先 $S[len + 1$~ $i]$ 和 $S[1$~ $i - len]$ 的长度不小于$len$ 且是 $len$ 的倍数。$S[len + 1$~ $i]$ 和 $S[1$~ $i - len]$ 以 $len$ 为长度错位对齐,以$len$ 为间隔取对应字符有
$S[len + 1$~ $2*len] = S[1$~ $len]$ ,以此类推得证。
$Codeforces - Anthem of Berland$
题意:给定一个包含?的字符串A,还有一个字符串B,问B最多可能在A中出现几次。
input
winlose???winl???w??win
output
5
DP+KMP
$dp[i]$ 表示 $0$ ~ $i$ 的字符串最多能出现几次 $B$
$cnt[i]$ 表示最后一次出现的以 $i$ 结尾 $B$ $0$ ~ $i$中出现 $B$ 的次数($A[i-len$~$i] = B$ )
求 $cnt[i]$ 可以用KMP
首先,不考虑最后一个B $cnt[i]$ 肯定大于等于 $cnt[i-lenB]$ 如果$i-lenB$ 前的某几个字符与 后面的字符也能凑成一个 $B$ 那么 $cnt[i]$ 就比 $cnt[i-lenB]$ 要大一 这样的情况就是求一下前缀数组的情况
| 例子 $A:abc | abcab$ $B:abcab$ |
具体来说就是
cnt[i] = dp[i - lenB];
for (int k = nxt[lenB]; k != -1; k = nxt[k]) {
cnt[i] = max(cnt[i], cnt[i - (lenB - k)]);
}
cnt[i]++;
$codeforces$ $471D$ $MUH$ $and$ $Cube$ $Walls$
给定两个数组表示形状,问第二个数组的形状能否在第一个数组中找到.若能找到,求出能找到几次
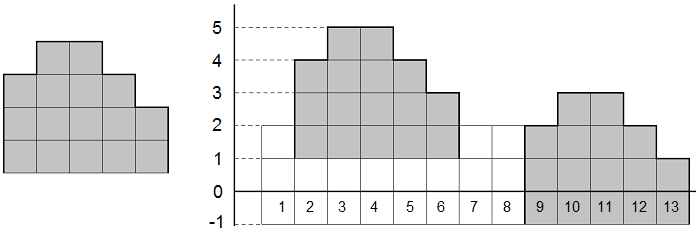
kmp,因为只需要形状相同,不需要考虑每个值的实际大小,只需要使得数组的前后差值相等,就能使得上边界构成的形状相同。 求出两个数组的相邻数差值构成的新数组,然后利用kmp求第二个差值数组在第一个差值数组中出现的次数,注意到若第二个数组就只有一个数,则在第一个数组任意位置都能构成相同的形状因此此时输出n即可
#include <cstdio>
using namespace std;
const int maxn = 2e5+10;
int pi[maxn];
int a[maxn], c[maxn], b[maxn], d[maxn];
void p_f(int* s, int n) {
pi[0] = 0;
for (int i = 1; i < n; i++) {
int j = pi[i - 1];
while (j > 0 && s[i] != s[j]) j = pi[j - 1];
if (s[i] == s[j]) j++;
pi[i] = j;
}
}
int main(){
int n, w;
scanf("%d %d",&n, &w);
for(int i = 0;i < n; i++){
scanf("%d", &a[i]);
if(i) c[i-1] = a[i] - a[i-1];
}
for(int i = 0;i < w; i++){
scanf("%d", &b[i]);
if(i) d[i-1] = b[i] - b[i-1];
}
if(w==1){
printf("%d\n", n);
}
else {
p_f(d, w-1);
int j = 0, ans = 0;
for(int i = 0;i < n-1; i++){
while(j>0&&c[i]!=d[j]) j = pi[j-1];
if(c[i] == d[j]) j++;
if(j==w-1){
//printf("%d %d\n", i, pi[j-1]);
j = pi[j-1];
ans++;
}
}
printf("%d\n", ans);
}
return 0;
}
2.最小表示法
给定一个字符串 $S$ , 如果我们不断把它的最后一个字符放到开头,最终会得到 $n$ 个字符串,称这 $n$ 个字符串是循环同构的。这些字符串中字典序最小的一个,称为字符串 $S$ 的最小表示。
用$B[i]$表示从 $i$ 开始的循环同构字符串,即 $S[i$~$n]+S[1$~$i-1]$。
首先,我们把这个字符串复制一份放到后面,记这个新的字符串为 $SS$ .
在对 $SS$ 比较的过程中如果在 $i + k$, $j + k$ 处发现不相等,假设 $SS[i+k] > SS[j+k]$ ,那么我们除了得知 $B[i]$ 不是最小表示,同时$B[i+1]$~$B[i+k]$ 也都不是。指针后移即可。
3.Trie(读作Try)
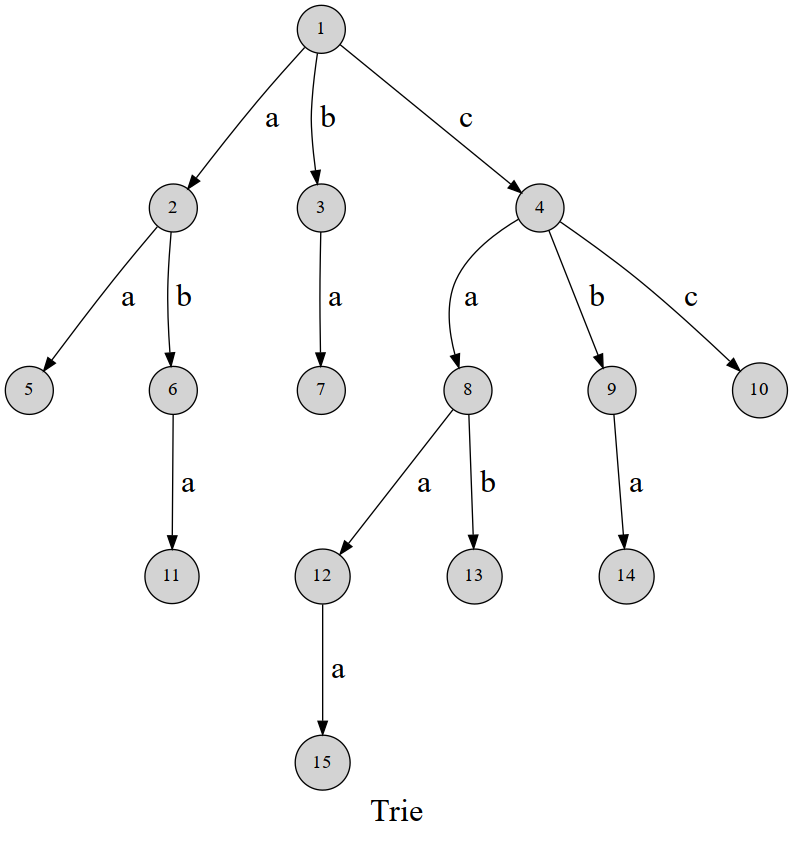
$trie[i][j] = k$, 编号为 $i$ 的节点第 $j$ 个孩子是编号为 $k$ 的节点, $i$ 与 $k$ 是建树时新插入的节点的编号
若都为大写或都为小写, $j$ 可取 $0-25$
void insert(char *s){
len = strlen(s);
root = 0;
for(int i = 0;i <len; i++){
int id = s[i] - 'a';
if(!trie[root][id]) //没有从root到id的编号 新建标号
trie[root][id] = ++root;
root = trie[root][id];
}
end[root] = 1;//标记结束
}
bool find(char *s){
len = strlen(s);
root = 0;
for(int i = 0;s[i]; i++){
int x = s[i] - 'a';
if(trie[root][x] == 0) return 0;
root = trie[root][x];
}
return end[root];
}
$The$ $XOR$ $Largest$ $Pair$
给定 $N$ 个整数 $A_1,A_2,…,A_N$ 中选出两个进行异或运算,得到结果最大多少?
解:考虑一个数转化为二进制后,要使它与另一个数异或后值最大,那就是在每一个二进制位上取反
我们将每一个所给的数转化为32位的二进制数(补前导 $0$)然后建立字典树(低位在下),对每个数,我们寻找其上述每位求反的数是否存在,如果不存在只能找与其相同的,那这一位上的值变为 $0$,这样可以找到与$Ai$异或后值最大的 $A_j$
$POJ 3764$
给定一棵 $N$ 个节点的树, 树上的每一条边都有一个权值。从树中选择两个点 $x$ 和 $y$ ,把从 $x$ 到 $y$ 的路径上的所有边权 $xor$ 起来,得到的结果最大是多少?
首先,我们可以求出每个点 $x$ 到根节点的路径上的所有边权 $xor$ 值 记为 $D[x]$
题目所要求的值就等于 $D[x]xorD[y]$ 问题就变成了从 $D[1]$ ~ $D[N]$ 这 $N$ 个数中选两个数, $xor$ 的结果最大,就是前一道题。
4.Manacher
求回文子串
p数组保存以当前字符为对称轴的回文半径
因为有可能回文串长为偶数,所以对称轴不是字符而是字符之间的空隙
于是我们在每两个字符间插入一个不会出现的字符($Ascill$为 $0$ 比如说)
bob -> #b#o#b#
但是这样会出现新的问题
求回文串的时候会比较当前回文串前一个字符与后一个字符,这样就会访问到$s[-1]$ 这个位置导致越界
所以我们在开头再加入一个不会出现的且与之前插入的不同的字符($Ascill$为 $1$ 比如说)
然后是求 $p[i]$
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
其中 $id$ 为当前所探索到的最右边那个回文串的对称轴位置
$mx$ 为最右端位置
如果 $mx > i$, 则 $p[i] = min( p[2 * id - i] , mx - i )$
否则,$p[i] = 1$
当 $mx - i > p[j]$ 的时候,以S[j]为中心的回文子串包含在以S[id]为中心的回文子串中,由于 $i$ 和 $j$ 对称,以$S[i]$为中心的回文子串必然包含在以$S[id]$为中心的回文子串中,所以必有 $p[i] = p[j]$,其中 $j = 2id - 1$,因为 $j$ 到 $id$ 之间到距离等于 $id$ 到 $i$ 之间到距离,为 $i - id$,所以 $j = id - (i - id) = 2id - i$
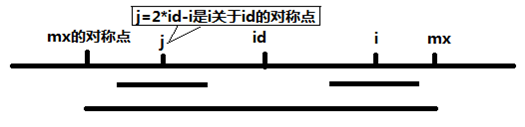
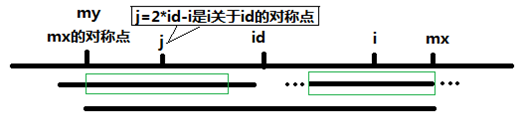
当 $p[j] >= mx - i$ 的时候,以$S[j]$为中心的回文子串不一定完全包含于以$S[id]$为中心的回文子串中,但是基于对称性可知,下图中两个绿框所包围的部分是相同的,也就是说以$S[i]$为中心的回文子串,其向右至少会扩张到$mx$的位置,也就是说 $p[i] = mx - i$。至于$mx$之后的部分是否对称,只能老老实实去匹配了
string t = "$#";
for (int i = 0; i < s.size(); ++i) {
t += s[i];
t += "#";
}
vector<int> p(t.size(), 0);
int mx = 0, id = 0, resLen = 0, resCenter = 0;
for (int i = 1; i < t.size(); ++i) {
p[i] = mx > i ? min(p[2 * id - i], mx - i) : 1;
while (t[i + p[i]] == t[i - p[i]]) ++p[i];
if (mx < i + p[i]) {
mx = i + p[i];
id = i;
}
if (resLen < p[i]) {
resLen = p[i];
resCenter = i;
}
}
题意:求这样一个回文串S,S = A + B 且 A, B都是回文串。问最长S
我们可以定义这么两个东西 1.:l[i]代表i位置所在回文串中的最右端的位置 2.:r[i]代表i位置所在回文串中的最左端的位置
一个从左到右遍历,一个从右到左,所以i所在的回文串不一定是同一个
我们可以算出来这个东西。 因此通过左右拼接就可以得到我们的双回文串了
for(int i=0;i<len;i++)
for(;pos<=i+p[i]-1;pos++)
l[pos]=i;//概念和上面讲的一样
pos=len;
for(int i=len-1;i>=0;i--)
for(;pos>=i-p[i]+1;pos--)
r[pos]=i;//概念同上面讲的一样
for(int i=0;i<len;i++)
ans=max(ans,abs(l[i]-r[i]));
5.exkmp(Z函数)
假设我们有一个长度为 $N$ 的字符串 $s$,该字符串的 Z函数 为一个长度为 $n$ 的数组,其中第 $i$ 个元素为满足从位置 $i$ 开始且为 $s$ 前缀的字符串的最大长度。
即, $z[i]$ 为 $s$ 和从 $i$ 开始的 $s$ 的后缀的最大公共前缀长度。
假设数组第一位为0
样例:
$Z(aaaaa) = [0,1,2,3,4]$
$Z(aaabaab) = [0,2,1,0,2,1,0]$
$Z(abacaba) = [0,0,1,0,3,0,1]$
朴素算法(O($n^2$))
vector<int> z_function_trivial(string s) {
int n = (int)s.length();
vector<int> z(n);
for (int i = 1; i < n; ++i)
while (i + z[i] < n && s[z[i]] == s[i + z[i]]) ++z[i];
return z;
}
高效算法(线性)
$z$ 数组的定义为取得最大的 $z[i]$ 使得 $s[0;z[i]-1] = s[i;i+z[i]-1]$
假设当前我们已经知道$s[0;r-l] = s[l;r]$ (;表示~)
可知$s[i-l;r-l] = s[i;r]$
然后可得$s[i-l;i-l+z[i-l]-1] = s[i;i+z[i-l]-1]$
那么 $z[i]$ 就至少等于 $z[i-l]$
当然还要注意,r后面的情况我们还不知道
所以$z[i] = min(z[i-1], r-i+1)$
然后再进行匹配 这样相当于让 $z[i]$ 赋了一个初值
至于为什么这样子会把时间复杂度降为 $O(n)$ 有兴趣的话可以自行百度
vector<int> z_function(string s) {
int n = (int)s.length();
vector<int> z(n);
for (int i = 1, l = 0, r = 0; i < n; ++i) {
if (i <= r) z[i] = min(r - i + 1, z[i - l]);
while (i + z[i] < n && s[z[i]] == s[i + z[i]]) ++z[i];
if (i + z[i] - 1 > r) l = i, r = i + z[i] - 1;
}
return z;
}
在一个字符串s中找一个子串,这个子串要符合的条件有三点,第一可以说这个子串是s的前缀,第二也可以说这个子串是s的后缀,第三也可以说这个子串既不是s的前缀也不是s的后缀。
#include <cstdio>
#include <string.h>
#include <algorithm>
using namespace std;
const int maxn = 1e6+10;
char s[maxn];
int z[maxn], n;
void z_f(char* s) {
for (int i = 1, l = 0, r = 0; i < n; ++i) {
if (i <= r) z[i] = min(r - i + 1, z[i - l]);
while (i + z[i] < n && s[z[i]] == s[i + z[i]]) ++z[i];
if (i + z[i] - 1 > r) l = i, r = i + z[i] - 1;
}
}
int main(){
scanf("%s", s);
n = strlen(s);
memset(z, 0, sizeof(z));
z_f(s);
int max1 = 0, maxp = 0;
for(int i = 0;i < n; i++){
if(z[i]>max1){
max1 = z[i];maxp = i;
}
}
int ans = 0;
//printf("%d %d\n", max1, maxp);
for(int i = n-1;i >= 0; i--){
if(i+z[i]-1 == n-1){
if(z[i]<max1||(z[i]==max1&&maxp!=i)){
//printf("%d\n", i);
ans = i;
}
}
}
if(ans!=0)printf("%s\n", s+ans);
else printf("Just a legend\n");
return 0;
}
例题
POJ2185
给你一个字符矩阵,求出它的最小覆盖子矩阵,即使得这个子矩阵的无限复制扩张之后的矩阵,能包含原来的矩阵。 即二维的最小覆盖子串。
一看这题,容易想出一种很直观的做法:求出每一行的最小覆盖子串长度,取所有行的最小覆盖子串长度的最小公倍数为宽;对列也同样操作求出高。由于POJ测试数据水了,所以过了。
但是,让我们来看一下下面这种情况
Input
2 8
ABCDEFAB
AAAABAAA
Output
12
第一行的最小覆盖子串长度为6,第二行为5 那么答案应该是60
但是第二行取6时 答案就为12
由于数据范围是R (1 <= R <= 10,000) C (1 <= C <= 75)那么直接暴力枚举重复子串的长度c,每列逐一检查是否与当前枚举的重复子串相对应。因此求宽度这个部分的时间复杂度为$O(R*C^2)$。
int get_width() {
char tmp[maxc];
int f[maxc];
memset(f, 0, sizeof f);
for (int row = 1; row <= r; row++) {
memset(tmp, 0, sizeof tmp);
for (int cir = 1; cir <= c; cir++) {
strncat(tmp, s[row] + cir - 1, 1);//取当前行前cir个字符
int cnt = 0;
for (int i = 0; i < c; i++)
cnt += (s[row][i] == tmp[i % cir]);//判断是否是长度为cir的覆盖子串
f[cir] += (cnt == c);
}
}
for (int i = 1; i <= c; i++)
if (f[i] == r) return i;//每一行都是长度为i的覆盖串
return c;
}
确定高度,把一行看成一个整体,行与行之间作KMP
int get_height() {
int next[maxr];
memset(next, 0, sizeof next);
next[0] = next[1] = 0;
int k = 0;
for (int i = 2; i <= r; i++) {
while (k != 0 && strcmp(s[i], s[k + 1]))
k = next[k];
if (!strcmp(s[i], s[k + 1])) ++k;
next[i] = k;
}
return r - next[r];
}